起
为了传送<某热门剧集>到欧洲, 将两集当天的<某热门剧集>上传到Linode的http服务器上, 并将链接地址告知了迅雷用户. 相当于使用服务器中转文件.
承
然而传完之后, http服务器的上传速度没有归零, 反而跳到30MBps, access_log中出现大量迷之ip, 请求都是两集<某热门剧集>, 于是马上删掉文件重启http服务. 由于<某热门剧集>地址只透露给了一个迅雷用户, 推断这个地址被迅雷发送给了其他正在下此资源的用户, 即盗链. 即使文件已经删掉, 仍有大量请求, 即使http服务器返回404也停不下来.
转
既然停不下来, 那想办法找点乐子吧. 弄两集葫芦娃, 处理成同样格式和大小, 然后让盗链用户下载, 这样他们是不是就会看着看着就被插播一段葫芦娃呢? 如果弄两集前两集的内容, 然后让盗链用户下载, 这样他们是不是看着看着就进入回忆篇了呢?
然而以上不是本文重点. 在地址被迅雷盗链之后5天, 收到了约600k盗链请求. 那么利用下这些数据, 做一次”大数据分析”好了.
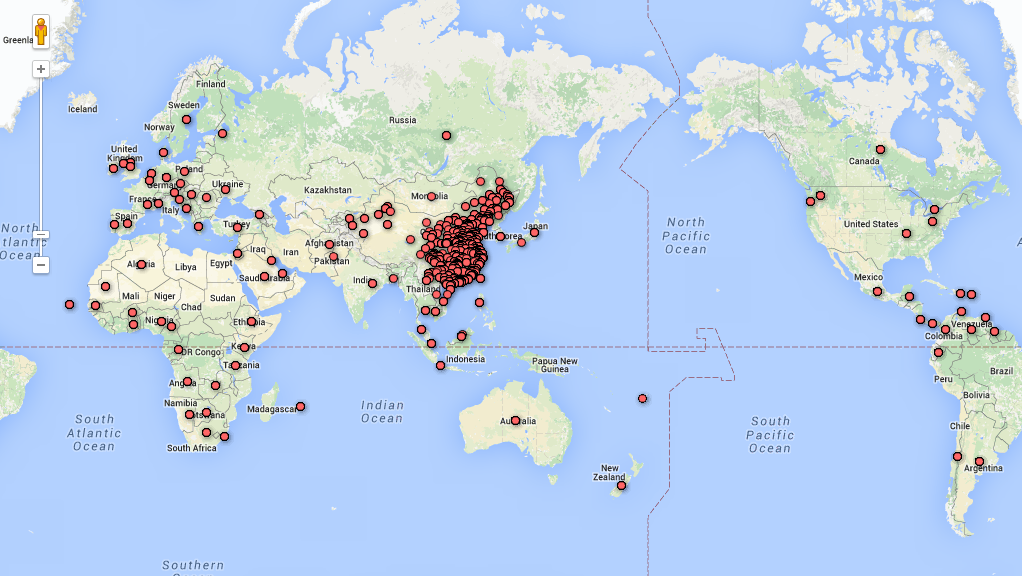
题图是Google Fusion Tables的Map快速绘制结果.
使用Python处理access log之后, 用Highcharts画图如下
总请求数量随时间的变化(每10分钟)
起初的请求数量很高, 之后请求数量锐减. 可能发现链接404之后, 就放弃通知新用户了. 然而即使5天之后, 一直有请求.
运营商分布
联通用户发起的请求甚至比未知ISP用户还要多, 远远超过移动和电信.
地理位置分布
盗链的同志来自五湖四海…
发起x个链接的IP数量y (左上角按钮切换范围)
大量的IP尝试了27或54次, 这可能是迅雷那边的固定尝试次数?
有的IP甚至尝试了五千多次, 或许是小区出口, 或者固定代理.
合
我是不是体验到了, 当年被迅雷盗链问题所困扰的中小网站站长的经历呢?
珍爱生命, 远离迅雷.
当初为了省事, 用HTTP+迅雷下载来利用服务器中转文件. 现在改用HTTP+aria2c. 由于win下aria2c是绿色软件, 可以通过命令行调用, 因此只要编写.bat批处理文件, 在其中写入URL即可. 直接运行.bat就进行下载, 比迅雷更方便.
特富phi(
地图真高端啊www